При попытке формализовать человеческие знания исследователи столкнулись с проблемой, затрудняющей использование традиционного математического аппарата для их описания. Существует целый класс описаний, оперирующих качественными характеристиками объектов (много, мало, сильный, очень сильный и т.п.). Эти характеристики обычно размыты, однако содержат важную информацию (например, «Одним из возможных признаков гриппа является высокая температура»).
Смысл термина нечеткость многозначен. Трудно претендовать на исчерпывающее определение этого понятия, поэтому рассмотрим лишь основные его компоненты, к которым относятся следующие:
- недетерминированность выводов;
- многозначность;
- ненадежность;
- неполнота;
- неточность.
Недетерминированность выводов. Это характерная черта большинства систем искусственного интеллекта. Недетерминированность означает, что заранее путь решения конкретной задачи в пространстве ее состояний определить невозможно. Поэтому в большинстве случаев методом проб и ошибок выбирается некоторая цепочка логических заключений, согласующихся с имеющимися знаниями, а в случае если она не приводит к успеху, организуется перебор с возвратом для поиска другой цепочки и т.д. Такой подход предполагает определение некоторого первоначального пути. Для решения подобных задач предложено множество эвристических алгоритмов, например, алгоритм А*, разработанный на этапах становления искусственного интеллекта.
Многозначность. Многозначность интерпретации — обычное явление в задачах распознавания. При понимании естественного языка серьезными проблемами становятся многозначность смысла слов, их подчиненности, порядка слов в предложении и т. п. Проблемы понимания смысла возникают в любой системе, взаимодействующей с пользователем на естественном языке. Распознавание графических образов также связано с решением проблемы многозначной интерпретации. При компьютерной обработке знаний многозначность необходимо устранять путем выбора правильной интерпретации, для чего разработаны специальные методы, например, метод релаксации, предназначенный для систематического устранения многозначности при интерпретации изображений.
Ненадежность знаний и выводов. Ненадежность знаний означает, что для оценки их достоверности нельзя применить двухбалльную шкалу (1 — абсолютно достоверные; 0 — недостоверные знания). Для более тонкой оценки достоверности знаний применяется вероятностный подход, основанный на теореме Байеса, и другие методы. Например, в экспертной системе MYCIN, предназначенной для диагностики и выбора метода лечения инфекционных заболеваний, разработан метод вывода с использованием коэффициентов уверенности. Широкое применение на практике получили нечеткие выводы, строящиеся на базе нечеткой логики, ведущей свое происхождение от теории нечетких множеств.
Неполнота знаний и немонотонная логика. Абсолютно полных знаний не бывает, поскольку процесс познания бесконечен. В связи с этим состояние базы знаний должно изменяться с течением времени. В отличие от простого добавления информации, как в базах данных, при добавлении новых знаний возникает опасность получения противоречивых выводов, т.е. выводы, полученные с использованием новых знаний, могут опровергать те, что были получены ранее. Еще хуже, если новые знания будут находиться в противоречии со «старыми», тогда механизм вывода может стать неработоспособным. Многие экспертные системы первого поколения были основаны на модели закрытого мира, обусловленной применением аппарата формальной логики для обработки знаний. Модель закрытого мира предполагает жесткий отбор знаний, включаемых в базу, а именно: БЗ заполняется исключительно верными понятиями, а все, что ненадежно или неопределенно, заведомо считается ложным. Другими словами, все, что известно базе знаний, является истиной, а остальное — ложью. Такая модель имеет ограниченные возможности представления знаний и таит в себе опасность получения противоречий при добавлении новой информации. Тем не менее, эта модель достаточно распространена; например, на ней базируется язык PROLOG. Недостатки модели закрытого мира связаны с тем, что формальная логика исходит из предпосылки, согласно которой набор определенных в системе аксиом (знаний) является полным (теория является полной, если каждый ее факт можно доказать, исходя из аксиом этой теории). Для полного набора знаний справедливость ранее полученных выводов не нарушается с добавлением новых фактов. Это свойство логических выводов называется монотонностью. К сожалению, реальные знания, закладываемые в экспертные системы, крайне редко бывают полными.
Неточность знаний. Известно, что количественные данные (знания) могут быть неточными, при этом существуют количественные оценки такой неточности (доверительный интервал, уровень значимости, степень адекватности и т.д.). Лингвистические знания также могут быть неточными. Для учета неточности лингвистических знаний используется теория нечетких множеств, предложенная Л. Заде в
Нечеткая логика
Нечеткая логика – это надмножество классической булевой логики, расширяющее ее возможности и позволяющее применить концепцию неопределённости в логических выводах. Она была введена Л.Заде как способ моделирования неопределенностей естественного языка. Концептуальное отличие нечеткой логики от классической заключается в том, что она интерпретирует не только значениями «истина» и «ложь», но и промежуточными значениями.
В основе нечеткой логики лежит теория нечетких множеств. В классической теории множеств, подмножество U множества S может быть определено как отображение элементов S в элементы множества {0, 1},
U: S ? {0, 1}
Это отображение может быть представлено как совокупность упорядоченных пар, с точно одной упорядоченной парой, сопоставленной с каждым элементом S. Первый элемент упорядоченной пары — элемент множества S, второй элемент — элемент из множества {0, 1}. Значение нуль используется, чтобы представить непринадлежность к множеству, а значение один используется для представления принадлежности. Истинность или ложность утверждения
X находится в U
определяется, исходя из упорядоченных пар, чей первый элемент — x. Утверждение истинно, если второй элемент упорядоченной пары — 1, и ложно, если это — 0. Точно так же нечеткое подмножество F множества S может быть определено как совокупность упорядоченных пар, первым элементом которых является S, а второй элемент находится в интервале [0, 1] с точно одной упорядоченной парой, представленной для каждого элемента S. Он определяет отображение элемента из множества S в значения на интервале [0, 1]. Это означает, что переход от полной принадлежности объекта классу к полной го непринадлежности происходит не скачком, а плавно, постепенно, причем принадлежность элемента множеству выражается числом из интервала [0, 1]. Значение нуль используется для представления полной непринадлежности, значение один используется для представления полной принадлежности, и значения между ними используется для представления промежуточных значений степени принадлежности. Множество S называется универсальным множеством нечеткого подмножества F. Отображение часто описывается с помощью функции принадлежности F. Степень, с которой утверждение
X находится в F
является истинным, определяется упорядоченной парой, первый элемент которой x. Второй элемент упорядоченной пары — степень истинности утверждения. Практически термины «функция принадлежности» и «нечеткое подмножество» взаимозаменяемы.
Л.Заде ввел одно из главных понятий в нечеткой логике — понятие лингвинистической переменной.
Лингвинистическая переменная — это переменная, значение которой определяется набором вербальных, то есть словесных, характеристик некоторого свойства.
Пример. Лингвинистическая переменная «рост» определяется через набор (карликовый, низкий, средний, высокий, очень высокий).
В литературе встречается такая запись:
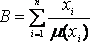 ,
,
где B – нечеткое множество;
m(x) – функция принадлежности;
xi – i-е значение базовой шкалы.
Функция принадлежности определяет субъективную степень уверенности эксперта в том, что данное конкретное значение базовой шкалы соответствует определяемому нечеткому множеству.
Пример. Определение нечеткого множества «высокая» для лингвинистической переменной «цена автомобиля» двумя экспертами.
«Высокая_цена_автомобиля_1» = 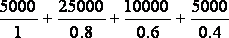
«Высокая_цена_автомобиля_2» = 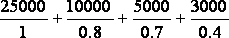
Для более строгого определения понятия лингвинистической переменной необходимо ввести понятие нечеткой переменной.
Нечеткая переменная характеризуется тройкой <a, X, A>, где a — наименование переменной; X — универсальное множество (область определения a); A — нечеткое множество на X, описывающее ограничения на значения нечеткой переменной a.
Лингвинистической переменной называется набор <b, T, X, G, M>, b — наименование лингвинистической переменной; T — множество ее значений (терм-множество), представляющих собой наименование нечетких переменных, областью определения каждой из которых является множество X, G — синтаксическая процедура, позволяющая оперировать элементами терм-множества T, в частности генерировать новые термы (значения); M — семантическая процедура, позволяющая превратить каждое новое значение лингвинистической переменной, образуемое процедурой G, в нечеткую переменную, то есть сформировать соответствующее нечеткое множество.
Для представления операций с нечеткими знаниями, выраженных при помощи лингвинистических переменных, существует много различных способов. Эти способы являются в основном эвристиками.
Стандартные определения в нечеткой логике (логике Заде):
Истинно (не x) = 1.0 – истинно (x);
Истинно (x и y) = минимум (истинно (x), истинно (y));
Истинно (x или y) = максимум (истинно (x), истинно (y)) .
Некоторые исследователи в области нечеткой логики используют другую интерпретацию операций И и ИЛИ, но определение операции НЕ не изменилось. Например, как в вероятностном подходе
ИЛИ (x, y) = x + y – x * y.
Нечеткое правило логического вывода представляет собой упорядоченную пару (А, В), где А — нечеткое подмножество пространства входных значений X, В — нечеткое подмножество пространства выходных значений Y. Как правило, оно имеют вид:
если цена велика и спрос низкий, то оборот мал,
где цена и спрос — входные переменные;
оборот — выходное значение;
велика, низкий и мал — функции принадлежности (нечеткие множества), определенные на множествах значений цены, спроса и оборота соответственно.
Нечеткие правила вывода образуют базу правил. Важно то, что в нечеткой управляющей системе в отличие от традиционной работают все правила одновременно, но степень их влияния на выход может быть различной. Принцип вычисления суперпозиции многих влияний на окончательный результат лежит в основе нечетких управляющих систем.
Процесс обработки нечетких правил вывода в управляющей системе состоит из четырех этапов:
- Вычисление степени истинности левых частей правил (между «если» и «то») — определение степени принадлежности входных значений нечетким подмножествам, указанным в левой части правил вывода.
- Модификация нечетких подмножеств, указанных в правой части правил вывода (после «то»), в соответствии со значениями истинности, полученными на первом этапе.
- Объединение (суперпозиция) модифицированных подмножеств.
- Скаляризация результата суперпозиции — переход от нечетких подмножеств к скалярным значениям.
Для определения степени истинности левой части каждого правила нечеткая управляющая система вычисляет значения функций принадлежности нечетких подмножеств от соответствующих значений входных переменных. Например, определение степени вхождения конкретного значения переменной цена в нечеткое подмножество велика, то есть истинность предиката «цена велика». Полученное значение истинности используется для модификации нечеткого множества, указанного в правой части правила. Для выполнения такой модификации используют один из двух методов: «минимум» (correlation-min encoding) или «произведение» (correlation-product encoding).
Первый метод ограничивает функцию принадлежности для множества, указанного в правой части правила, значением истинности левой части. Во втором методе значение истинности левой части используется как коэффициент, на который умножаются значения функции принадлежности.
Результат выполнения правила — нечеткое множество. Говоря более строго, происходит ассоциирование переменной и функции принадлежности, указанной в правой части правила.
Выходы всех правил вычисляются нечеткой управляющей системой отдельно, однако в правой части нескольких из них может быть указанна одна и та же нечеткая переменная. При определении обобщенного результата необходимо учитывать все правила, для этого система производит суперпозицию нечетких множеств. Эта операция называется нечетким объединением правил вывода. Например, правая часть правил
если цена мала, то спрос велик
если цена велика, то спрос мал
содержит одну и ту же переменную — спрос. Два нечетких подмножества, получаемые при выполнении этих правил, должны быть объединены управляющей системой.
Традиционно суперпозиция функций принадлежности нечетких множеств определяется как их объединение. Другой метод суперпозиции состоит в суммировании значений всех функций принадлежности. Самым простым (но и наименее часто используемым) является подход, когда суперпозиция не производится. Выбирается одно из правил вывода, результат которого используется в качестве интегрального результата.
Конечный этап обработки базы правил вывода — переход от нечетких значений к конкретным скалярным. Процесс преобразования нечеткого множества в единственное значение называется «скаляризацией» или «дефазификацией» (defuzzification).
При переходе от нечеткого вывода к четкому выходу могут использоваться различные способы:
- метод центра тяжести (определяется абсцисса центра тяжести кривой по функцией принадлежности);
- метод первого максимума (выбирается первый элемент нечеткого множества при котором достигается максимум значения функции принадлежности);
- метод среднего максимума;
- метод наименьшего максимума.
Чаще всего используется «центр тяжести» функции принадлежности нечеткого множества. Конкретный выбор методов суперпозиции и скаляризации осуществляется в зависимости от желаемого поведения нечеткой управляющей системы.
Кроме описанного алгоритма нечеткого вывода используются другие способы:
- алгоритм Мамдани (Mamdani);
- алгоритм Цукамото (Tsukamoto);
- алгоритм Сугэно (Sugeno);
- алгоритм Ларсена (Larsen).
Определим в общем области применения нечёткого управления.
Использование нечеткого управления рекомендуется:
- для очень сложных процессов, когда не существует простой математической модели;
- для нелинейных процессов высоких порядков;
- если должна производиться обработка (лингвистически сформулированных) экспертных знаний.
Использование нечёткого управления не рекомендуется применять в следующих ситуациях:
- приемлемый результат может быть получен с помощью общей теории управления;
- уже существует формализованная и адекватная математическая модель;
- проблема не разрешима.
Нечеткая логика используется при создании систем, понимающих тексты на естественном языке, при создании планирующих систем, опирающихся на неполную информацию, при обработке зрительных сигналов, при управлении техническими, социальными и экономическими системами, в системах искусственного интеллекта и робототехнических системах:
- автоматическое управление воротами плотины на гидроэлектростанциях;
- упрощенное управление роботами;
- наведение телекамер при трансляции спортивных событий;
- замена экспертов при анализе работы биржи;
- эффективное и стабильное управление автомобильными двигателями;
- управление экономичной скоростью автомобилей;
- улучшение эффективности и оптимизация промышленных систем управления;
- оптимизированное планирование автобусных расписаний;
- системы архивации документов;
- системы прогнозирования землетрясений;
- медицина: диагностика рака;
- сочетание методов нечеткой логики и нейронных сетей;
- распознавание рукописных символов в карманных компьютерах (записных книжках);
- распознавание движения изображения в видеокамерах;
- автоматическое управление двигателем пылесосов с автоматическим определением типа поверхности и степени засоренности;
- управление освещенностью в камкодерах;
- компенсация вибраций в камкодерах;
- однокнопочное управление стиральными машинами;
- распознавание рукописных текстов, объектов, голоса;
- вспомогательные средства полета вертолетов;
- моделирование судебных процессов;
- САПР производственных процессов;
- управление скоростью линий и температурой при производстве стали;
- управление метрополитенами для повышения удобства вождения, точности остановки и экономии энергии;
- оптимизация потребления бензина в автомобилях;
- повышение чувствительности и эффективности управления лифтами;
- повышение безопасности ядерных реакторов.
На рынке представлено множество программных продуктов, использующих нечеткую логику: Бизнес-Прогноз, CubiCalc, RuleMaker, FIDE, FuzzyNET, FuzzyCLIPS, FuNeGen, NEFCON-I, Fuzzy Logic Toolbox системы MatLab, FuzzyXL, FuzzyCalc и др.
Моделирование неопределенности в рассуждениях
Рассмотрим ситуацию. Пусть используется правило
если (А), то (В),
предположим, что никакие другие правила и посылки не имеют отношения к рассматриваемой ситуации.
Неопределенность может быть двух типов:
- неопределенность в истинности самой посылки (например, если степень уверенности в том, что A истинно составляет 90%, то какие значения примет В);
- неопределенность самого правила (например, мы можем сказать, что в большинстве случаев, но не всегда, если есть А, то есть также и В).
Еще более сложная ситуация возникает в случае, если правило имеет вид:
если (А и В), то (С),
где мы можем с некоторой степенью быть уверены как в истинности каждой из посылок (А, В), а тем более их совместного проявления, так и в истинности самого вывода.
Существуют четыре проблемы, которые возникают при проектировании и создании систем с неопределенными знаниями:
- Как количественно выразить степень определенности при установлении истинности (или ложности) некоторой части данных?
- Как выразить степень поддержки заключения конкретной посылкой?
- Как использовать совместно две (или более) посылки, независимо влияющие на заключение?
- Как быть в ситуации, когда нужно обсудить цепочку вывода для подтверждения заключения в условиях неопределенности?
Рассмотрим возможности использования теории вероятности при выводе в условиях неопределенности — байесовское оценивание.
Для рассмотрения теоремы Байеса приведем некоторые фундаментальные понятия теории вероятностей.
Пусть А некоторое событие реального мира. Совокупность всех элементарных событий называется выборочным пространством или пространство событий W. Вероятность события А, обозначается р(А) и каждая вероятностная функция р должна удовлетворять трем аксиомам:
1. Вероятность любого события А является неотрицательной, то есть
p(A) ? 0 для " A ? W.
2. Вероятность всех событий выборочного пространства равна 1, то есть
p(W)=1.
3. Если k событий А1, А2, … , Аk являются взаимно независимыми (то есть не могут подойти одновременно), то вероятность, по крайней мере, одного из этих событий равна сумме отдельных вероятностей, или
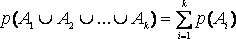 .
.
Аксиомы 1 и 2 можно объединить, что дает
0 ? p(A) ? 1 для " A ? W.
Это утверждение показывает, что вероятность любого события находится между 0 и 1. По определению, когда р(А) = 0, то событие А никогда не произойдет. В том случае и когда р(А) = 1 , то событие А должно произойти обязательно. Дополнение к А, обозначаемое (¬A), содержит совокупность всех за исключением А. Так как А и ¬A являются взаимонезависимыми (то есть W событий в А? ¬A= W) то из аксиомы 3 следует
р(А) + р(¬A) = р(А ? ¬A) = р(W ) = 1 .
Переписывая это равенство в виде р(¬A) = 1 – р(А), мы получает путь для получения р(¬A) из р(А). Предположим теперь, что В ? W некоторое другое событие. Тогда вероятность того, что произойдет А при условии, что произошло В записывается в виде р(А | B) и называется условной вероятностью события А при заданном событии В. Вероятность того, что оба события А и В произойдут р(А?В) называется совместной вероятностью событий А и В. Условная вероятность р(А|B) равна отношению совместной вероятности р(А?В) к вероятности события В, при условии, что она не равна 0, то есть
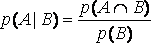 .
.
Аналогично условная вероятность события В при условии А, обозначаемая р(В | А) равна
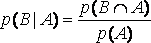
и таким образом
p(B?A) = p(B|A)  p(A).
p(A).
Так как совместная вероятность коммутативна (то есть от перестановки мест сумма не меняется), то
p(A?B)= p(B?A)= p(B|A) p(A).
Подставляя это равенство в ранее полученное выражение для условной вероятности р(А| В ) получим правило Байеса
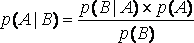 .
.
В ряде случае наше знание того, что произошло событие B, не влияет на вероятность события A (или наоборот A на B). Другими словами, вероятность события А не зависит от того, что произошло или нет событие В, так что р(А | В) = р(А) и р(В | А) = р(В). В этом случае говорят, что события А и В являются независимыми.
Приведенные выше соотношения предполагают определенную связь между теорией вероятностей и теорией множеств. Если А и В являются непересекающимися множествами, то объединение множеств соответствует сумме вероятностей, а пересечение — произведению вероятностей, то есть
р(А ? В) = р(А) + р(В),
р(А ? В) = р(А) ? р(В).
Без предположения независимости эта связь является неточной и формулы должны содержать дополнительные члены включения и исключения (так например, р(А?В)=р(А)+ р(В) – р(А?В) ). Продолжая теоретико-множественное обозначение B можно записать как
В = (В ? А) ? (В ? ¬A).
Так как это объединение явно непересекающееся, то
р(В)=р((В?А)?(В?¬A))=р(В?А)+ р(В?¬A) = р(В|А) р(А) + р(В|¬A)р(В)
Возвращаясь к обозначению событий, а не множеств, последнее равенство может быть подставлено в правило Байеса
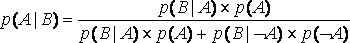 .
.
Это равенство является основой для использования теории вероятности в управлении неопределенностью. Оно обеспечивает путь для получения условной вероятности события B при условии А. Это соотношение позволяет управлять неопределенностью и «делать вывод «вперед и назад».
Неопределенность можно промоделировать, приписывая утверждениям некоторые характеристики, отличные от «истина» или «ложь». Степень уверенности может выражаться в форме действительного числа, заключенного в некотором интервале, например между –1 и +1. Такую числовую характеристику называют по-разному: коэффициент определенности, коэффициент уверенности, степень доверия. Границы интервала обозначают следующее:
+1 — система в чем-то полностью уверена;
0 — у системы нет знаний об обсуждаемой величине;
–1 — высказанная посылка или заключение полностью неверно.
Промежуточные величины отражают степень доверия или недоверия к указанным ситуациям. Коэффициент неопределенности в выводимом заключении представляет собой число, которое должно объединить и отразить источники внутренних ошибок.
Приведем схему приближенных рассуждений, реализованную в MYCYN, и в дальнейшем в EMYCIN.
Основной вычислительный прием, который используется для нахождения коэффициента определенности сводится к следующему:
t(заключение) = ct(посылка)*ct(импликация).
Для импликации вида
ЕСЛИ (е1 и е2) ТО (с)
согласно оценке, сделанной в EMYCIN, коэффициент определенности посылки равен коэффициенту определенности наименее надежной из посылок, то есть
ct(e1 и e2)= min(ct(e1), ct(e2)).
Для
ЕСЛИ (е1 или е2) ТО (с)
общее правило комбинирования, по которому вычисляется коэффициент определенности посылки, заключается в том, что коэффициент определенности дизъюнкции равен коэффициенту ее сильнейшей части, то есть
ct(e1 или e2)= max(ct(e1), ct(e2)).
В случае, когда используются два правила для поддержки, например:
ЕСЛИ (е1) ТО (с) ct(заключения)=0.9
ЕСЛИ (e2) ТО (с) ct(заключения)=0.8
Был предложен следующий механизм:
ctotal= коэффициент определенности из правила 1
+ коэффициент определенности из правила 2
– (коэффициент определенности из правила 1)
*(коэффициент определенности из правила 2)
При вычислении итоговых коэффициентов необходимо учитывать знаки. В EMYCIN был предложен следующий механизм.
- если оба коэффициента определенности положительны: ctotal= ct1 + ct2 – ct1*ct2;
- если оба коэффициента определенности отрицательны: ctotal= ct1 + ct2 + ct1*ct2;
- когда отрицателен один коэффициент: ctotal= (ct1 + ct2)/ (1 – min(abs(ct1),abs(ct2));
- когда одна определенность равна +1, а другая –1: ctotal= 0.
Помимо использования коэффициентов уверенности, в литературе описаны и иные подходы, альтернативные вероятностному. В частности, много внимания уделяется нечеткой логике (fuzzy logic) и теории функций доверия (belieffunctions), что положило начало одной из ветвей искусственного интеллекта — мягкие вычисления (soft computing).
Обратимость правил
Применение биполярных коэффициентов определенности может привести к нереальным результатам, если правила сформулированы неточно, поэтому ввели еще одно ограничение на правила — обратимость.
Все правила попадают в одну из двух очень важных категорий. Правила первой категории — обратимые. Одной из характеристик такого правила является его применимость к любому вероятностному значению, которое может быть связано с посылкой. Правила второй категории считаются необратимыми. Эти правила «работают» только при положительных значениях посылках. Если же ее значение отрицательно, правило применять нельзя.
Рассмотрим правила:
- Если это последняя модель компьютера, то в нем есть встроенный модем.
- Если это последняя модель компьютера, то в нем есть дисковод.
Первое правило сохраняет свое значение, когда и посылка, и заключение отрицательны. «Если это не последняя модель компьютера, то в нем нет встроенного модема». Значит это правило обратимо.
Второе же правило теряет смысл при отрицании посылки и заключения. «Если это не последняя модель компьютера, то в нем нет дисковода». Второе правило необратимо.
При создании правил необходимо всегда проверять их на обратимость и соответствующим образом помечать. Например
ЕСЛИ (е1) ТО (с1) ct(заключения)=0.9 (nrev)
ЕСЛИ (e2) ТО (с2) ct(заключения)=0.8 (rev)