Файлом называется набор логически связанных данных, находящийся в форме, удобной для хранения и обработки вычислительной системой. Файл представляет собой совокупность логических записей.
Когда речь идет о записях, входящих в состав файла, слово «логическая» часто опускают. Каждая запись файла содержит данные, имеющие конкретное назначение. В файлах, использующихся в целях учета запасов, каждая запись может представлять совокупность данных, относящихся к одному наименованию изделия. В организованном администрацией учебного заведения файле успеваемости студентов запись может содержать имя студента, его учетный номер, номер курса и экзаменационные оценки. Записи банковских учетных файлов могут содержать, например, такие данные, как номер клиента, его имя, текущий счет и сведения о проделанных им операциях за последний месяц. Записи файлов налогового управления могут состоять из сумм, взимающихся с определенных налогоплательщиков в текущем году. В настоящее время многие задачи программирования связаны с организацией и управлением файлами.
Значительная часть операционной системы предназначена для облегчения пользователю задачи управления и обработки данных. Однако операционной системе приходится иметь дело и с большим количеством иной информации. Сюда входят тексты исходных программ на машинном языке, библиотеки подпрограмм, входные данные выполняемых заданий и их вывод. Данные для обработки операционной системой могут быть представлены в виде наборов данных. Набор данных является наиболее крупной совокупностью информации, с которой оперирует система, и представляет собой множество данных, представленное в памяти некоторым специальным образом, вместе с дополнительной управляющей информацией, обеспечивающей возможность доступа к произвольному элементу этого множества. Каждая операционная система работает с наборами, имеющими одну из нескольких допустимых структур.
Для управления собственными файлами пользователи обычно используют возможности операционной системы. Тип используемой структуры определяет способ организации самого набора данных. Мы коротко охарактеризуем способы организации наборов данных, однако прежде попытаемся более внимательно рассмотреть отношения, существующие между отдельными логическими записями файла и операциями ввода-вывода.
Блок и записи
Как уже упоминалось, файлы состоят из одной или более логических записей. В качестве записи может выступать выводимая на устройство печати строка или содержимое одной перфокарты. Если речь идет о программе на языке ассемблера, то здесь записью является предложение исходного языка, имеющее длину 80 байтов. Запись файла, содержащая информацию о некотором студенте, может занимать 500 байтов. Вообще говоря, длина записей, так же как и содержимое, определяется назначением файла.
Физическая запись, или блок, представляет собой информацию, передаваемую устройством ввода или вывода за одну операцию. Для устройства чтения с перфокарт или выходного перфоратора блок состоит из 80 байтов, поскольку именно 80 байтов кодируются одной перфокартой. Блоком для устройства печати обычно является 132-байтовая строка. В такого рода устройствах, т. е. устройствах, где размеры блока строго определены самой аппаратурой, количество логических записей в блоке не может меняться и на один блок всегда приходится ровно одна запись. Такие устройства называются устройствами для единичных записей. На других устройствах, например, таких, какими являются магнитный диск и магнитная лента, размеры блока строго не определены. В этих случаях они выбираются самими программистами. Физические записи не обязательно совпадают по размерам с логическими. Формат записей в наборе данных задается отношением между размерами соответствующих записей и блоков.
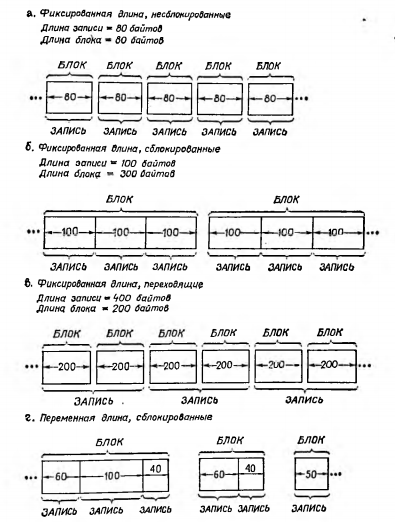
Рис. 17.1. Форматы записей.
В случаях, когда физические и логические записи по размерам совпадают, говорят, что записи не сблокированы. О сблокированном формате данных говорят в случае, если на одну физическую запись приходится более одной логической. Может встретиться также случай, когда размеры отдельных записей превышают размеры блоков. Записи в таком наборе называют переходящими.
Размер блока в наборе данных не обязательно является постоянной величиной. В этом случае говорят о блоках переменной длины, а значения величин, характеризующих размеры блоков, записываются внутри самих блоков. Если все блоки в наборе по размеру одинаковы, то говорят о наборе данных с блоками фиксированной длины.
На практике встречаются самые различные комбинации размеров блоков и отдельных записей. Некоторые возможные случаи приведены на рис. 17.1. Набор данных, изображенный на рис. 17.1,а может соответствовать, например файлу перфокарт. Длина каждого блока равна 80 байтам, в каждом из них ровно по одной логической записи. Набор, приведенный на рис. 17.1,6, составлен из 100-байтовых записей. Блоки этого набора имеют длину 300 байтов. Это значит, что в процессе ввода или вывода данных этого набора в рамках одной операции будет соответственно введена или выведена информация, составляющая 300 байтов. При обработке набора программой пользователя или программами операционной системы блоки будут разбиты на отдельные записи. На рис. 17.1,в изображен набор данных с переходящими записями постоянной длины. Ввод или вывод произвольной записи предполагает выполнение двух операций ввода-вывода. Набор данных рис. 17.1,г составлен из записей переменной длины. Более того, переменными в данном случае являются и длина отдельного блока, и количество записей в нем. Задача разбиения каждого блока на записи снова возлагается на обрабатывающую программу.
Способы организации наборов данных
Познакомившись с различными возможностями разбиения наборов данных на составные части — блоки и записи,— перейдем теперь к рассмотрению вопросов, связанных с общей структурой набора. Под организацией набора понимается взаимное расположение составляющих его блоков и отношения, связывающие каждый из блоков и набор данных в целом. Выбор некоторого определенного способа организации набора зависит от нескольких факторов. Сюда входят и тип устройства, на котором хранится набор, и порядок считывания отдельных записей и, наконец, цель, которая преследуется при создании набора.
Последовательная организация. Некоторые периферийные устройства, например накопители на магнитной ленте или устройства с единичными записями, однозначно определяют способ организации соответствующего набора данных. Записи в данном случае обрабатываются именно в том порядке, в котором они хранятся. Устройство чтения с перфокарт вводит исходный массив карту за картой именно в той последовательности, в какой он подготовлен для ввода. Устройство печати распечатывает строку за строкой в том порядке, в каком они поступают к нему. На магнитную ленту приходящая информация записывается в виде блоков также в порядке поступления. Последующий ввод с ленты будет проходить в порядке размещения блоков на ней.
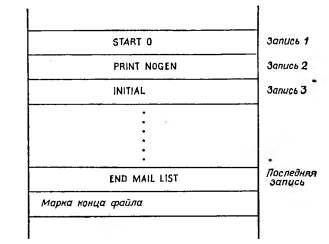
Рис. 17.2. Файл с последовательной организацией.
С другой стороны, устройства прямого доступа, такие, как, например, накопители на магнитных дисках, дают возможность производить запись и считывание блоков, находящихся в произвольном месте. Для этого необходимо лишь указать адрес записи. Другими словами, обработка записей набора может проходить в произвольном порядке при условии, конечно, что нам известны адреса их размещения или адреса, по которым они должны быть размещены. Однако в большинстве приложений физический порядок записей в наборе совпадает с порядком, в котором желательно производить их обработку. Крайне редко рассмотрение отдельных записей, составляющих предложения исходной программы, требуется проводить не в том порядке, в котором они написаны. То же самое можно сказать по отношению к написанным на машинном языке объектным и загрузочным модулям.
Файлы, в которых обработка отдельных записей проходит в порядке их физического размещения, называются последовательными. При создании последовательного файла или добавлении к нему новых записей порядок записи информации совпадает с порядком ее поступления на периферийное устройство. Считывание записей последовательного файла происходит в порядке их расположения в нем. Обработка информации в порядке ее размещения на устройстве или в памяти носит название последовательной обработки.
Последовательные файлы хранятся в наборах данных с последовательной организацией. На рис. 17.2 приведен пример последовательно организованного набора данных. За последним блоком набора следует специальный блок, называемый ленточной маркой и являющийся признаком конца набора данных. При добавлении к последовательному набору очередного блока ленточная марка перекрывается этим блоком и новая марка записывается сразу же за ним. При вводе некоторого набора данных считывание записей происходит именно в том порядке, в котором они записаны в наборе, ввод происходит до тех пор, пока не будет встречена ленточная марка.
Библиотечная организация. Мы уже упоминали о существовании некоторых системных библиотек, имеющих большое значение для пользователей. Сюда относятся системная макробиблиотека, библиотека каталогизированных процедур, библиотеки системных программ и тестовых примеров. Каждый раздел библиотеки представляет собой последовательный набор данных. Например, библиотека каталогизированных процедур системы OS содержит такие разделы, как ASMFCLG, FORTGCLG и COBUCG.
Запрос содержимого библиотек происходит с использованием имен разделов. Например, при обработке макрокоманды INITIAL ассемблер запрашивает раздел с именем INITIAL, находящийся в системной макробиблиотеке. Набор данных, состоящий из одного или нескольких разделов и организованный таким образом, что доступ к отдельным его разделам осуществляется по их именам, называется библиотечным, набором.
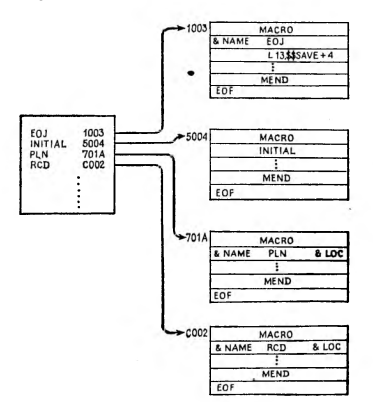
Рис. 17.3. Структура библиотечного набора данных, содержащего специальные макро, используемые в этой книге.
Библиотечные наборы данных хранятся на устройствах прямого доступа. Это позволяет запрашивать отдельные разделы, указывая лишь адреса их начала. Для облегчения поиска раздела библиотеки системой создается специальная таблица, называемая оглавлением, в которой имени каждого раздела набора данных соответствует адрес его начала. На рис. 17.3 приведен пример структуры библиотечного набора. Если запрашивается некоторый раздел библиотеки, то система просматривает оглавление в поисках соответствующего имени. Затем определяется связанный с данным именем адрес и уже он непосредственно используется для определения местонахождения последовательного набора данных, который представляет требуемый раздел.
Операционная система предоставляет пользователю специальные программы для создания и ведения собственных библиотечных наборов. OS также использует библиотечные наборы данных для ведения собственных библиотек. Работа с библиотеками в системе DOS мало чем отличается от предусмотренной в OS, однако DOS не содержит специальных средств, позволяющих пользователям создавать собственные библиотечные наборы и выполнять работы по их ведению.
Индексно-последовательная организация. В некоторых применениях бывает очень удобно пользоваться' как последовательной обработкой набора, выбирая отдельные записи в том порядке, в каком они хранятся в некотором устройстве, так и произвольной обработкой вне связи с расположением отдельных записей, считывая, добавляя и изменяя записи. Вспомним нашу программу обработки учетной информации. Мы должны были хранить в памяти записи, соответствующие каждому имеющемуся в наличии наименованию товара, по одной записи на каждое наименование. Каждое наименование было связано с соответствующим номером, использовавшимся в качестве ключа. Записи в файле при этом были расположены в порядке возрастания числового значения ключей. В конце каждой недели выдавался отчет о состоянии файла на текущий момент. Отчет составляли записи в последовательном порядке. Поскольку записи в файле были упорядочены по возрастанию ключей, то порядок записей в отчете, конечно, был тем же самым, что облегчало поиск в нем строки, соответствующей определенному наименованию.
В течение недели ситуация, однако, могла меняться: компания могла произвести или закупить совершенно новые товары, старые товары могли постепенно продаваться. Все это требует внесения изменений в записи учетного файла. Для того чтобы внести изменение в некоторую запись, ее сначала нужно найти. Для нахождения записи можно организовать просмотр всего файла с самого начала до тех пор, пока требуемая запись не будет обнаружена. Однако, если файл содержит уже несколько тысяч записей, такой просмотр всякий раз, когда требуется внесение изменения в некоторую запись, может оказаться слишком расточительным с точки зрения машинного времени.
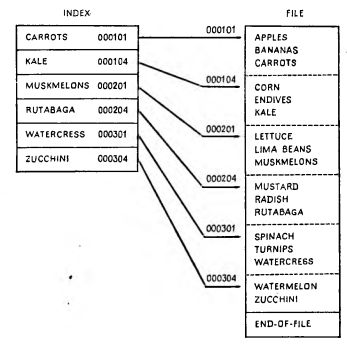
Рис. 17.4. Структура файла с индексно-последовательной организацией.
Фактически нужен такой способ организации набора данных, при котором доступ к отдельным записям в нем можно осуществлять как последовательно, так и с использованием ключей.
Таким способом организации данных является индексно-последовательная организация. При создании индексно-последовательного набора данных сначала записи файла упорядочиваются по ключам. В нашем примере, связанном с обработкой учетной информации, в качестве ключа записи будет использоваться соответствующий учетный номер. Затем производится последовательный вывод записей. Они помещаются системой на устройство прямого доступа. При этом строится один или несколько индексов. Если это удобно, обработка созданного таким образом набора может проводиться последовательно в порядке поступления записей на соответствующее устройство. С другой стороны, каждую конкретную запись можно запросить и по ключу, при этом используются индексы, построенные системой для ускорения поиска требуемой записи.
На рис. 17.4 приведен пример одноиндексной организации набора данных. Исходный файл разбит на подфайлы, каждому из которых соответствует определенная строка в таблице индексов. В такой строке содержится информация о ключе последней и адресе первой записи подфайла. Если происходит запрос записи с некоторым заданным значением ключа, то система сначала просматривает таблицу индексов в поисках первой строки, содержащей большее или равное данному значение. Требуемая запись принадлежит подфайлу, соответствующему этой строке, поэтому дальнейший поиск производится лишь среди элементов этого подфайла.
Система обладает возможностью добавлять новые записи в соответствующее место файла и удалять старые записи. Таким образом, индексно-последовательная организация значительно расширяет возможности обработки файлов. Записи могут обрабатываться как последовательно, так и в произвольном порядке. Все это предполагает, однако, упорядоченность записей в исходном файле.
Прямая организация. Если непосредственные адреса, по которым происходит размещение отдельных записей файла, задаются самим пользователем, то говорят о прямой организации набора данных. Обычно ключи служат для определения либо точного адреса записи, либо области, в пределах которой запись может находиться. Прямая организация дает возможность наиболее быстрого доступа к отдельным записям файла, но при этом вся ответственность за создание и ведение набора данных возлагается на пользователя. Прямая организация используется в тех случаях, когда необходимо производить работу с файлами, имеющими отличную от создаваемых операционной системой структуру.
Методы доступа
В разд. 17.4 будут описаны периферийные устройства и способы непосредственного программирования работы этих устройств. Однако на самом деле крайне редко приходится программировать на таком низком уровне. Вместо этого для организации различного рода обменов между памятью и периферийными устройствами, а также для создания и ведения наборов данных различной организации используются специальные системные программы, носящие название методов доступа. Команда ввода-вывода, использующая методы доступа, представляет собой обращение к некоторому набору системных программ, называемых супервизором ввода-вывода. Сами операции ввода-вывода выполняются уже непосредственно супервизором ввода-вывода с использованием связанных с ним подпрограмм. Фактически это означает, что при использовании методов доступа исчезает необходимость заботиться о конкретных деталях, связанных с выполнением операций ввода-вывода, об этом заботятся сами методы доступа.
В каждой операционной системе предусмотрено несколько методов доступа. Выбор какого-либо конкретного метода зависит от самой операционной системы, от организации обрабатываемого набора данных и, наконец, от требуемого способа буферизации.
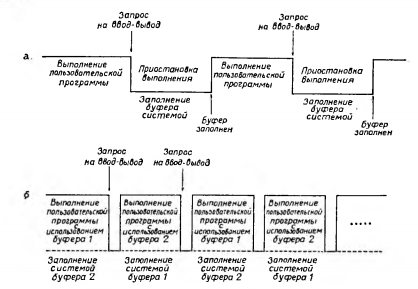
Рис. 17.5. (а) Простая буферизация задерживает выполнение программы до заполнения буфера, (б) Применение нескольких буферов обеспечивает совмещение выполнения программы и передачи данных.
Буферы. Буферами называются области памяти, предназначенные для размещения введенной с периферийного устройства информации или информации, подготовленной для вывода на периферийное устройство. В наиболее часто встречающемся случае вместе с запросом на ввод задается адрес буфера. Супервизор ввода-вывода выполняет непосредственный ввод блока с некоторого устройства в буфер. Если же мы хотим произвести вывод, то нам самим нужно позаботиться о соответствующем содержимом буфера. Когда данные подготовлены, посылается запрос на выполнение вывода, снабженный адресом буфера; сам вывод осуществляется уже непосредственно системой.
На рис. 17.6,а изображена последовательность событий, происходящих при периодическом запросе ввода в единственный буфер. Ввод запрашивается программой пользователя. Поскольку, скорее всего, работа программы пользователя не может быть продолжена до окончания обмена, супервизор временно приостанавливает ее выполнение до окончания обмена.
Выполнение операций ввода-вывода даже самыми быстрыми устройствами проходит относительно медленно, за это время процессор обычно может выполнить тысячи операций. Таким образом, использование всего лишь одного буфера значительно замедляет выполнение программы. Однако не надо думать, что, пока проходит ввод-вывод, процессор не в состоянии выполнять какие-либо иные операции. Как мы увидим в разд. 17.4, ЭВМ Систем 360 и 370 допускают одновременную работу процессора и периферийных устройств. В таких случаях говорят о совмещении выполнения операций ввода-вывода с выполнением обычных команд программы.
Возможность подобного совмещения можно удачно использовать, производя обмены, например, с двумя буферами. Пример такого использования изображен на рис. 17.5,6. При последовательной обработке супервизор организует ввод информации в том порядке, в котором она находится в файле. Таким образом, система фактически может, «предвидя» следующие запросы, заполнять буфер еще до получения заказа на ввод. Фактически, если обработка данных производится программой пользователя не быстрее, чем система может заполнять и освобождать буферы, то использование сразу нескольких буферов позволяет свести до минимума потери, возникающие в связи с необходимостью выполнения операций ввода-вывода. Использование нескольких буферов также позволяет увеличить общую скорость вывода информации.
Однако лишь при последовательной обработке данных использование нескольких буферов может дать выигрыш во времени. Если обработка данных производится в произвольной, случайной последовательности, то, что мы назвали «предвидением» системы, теряет смысл.
Каждая операционная система предусматривает наличие нескольких методов доступа. Степень необходимого участия программиста в решении многих вопросов, связанных с использованием буферов, в большой степени зависит от применяемого метода доступа. Некоторые методы доступа позволяют пользователям вообще не заботиться о буферах, выполняя всю необходимую работу автоматически. В других случаях управление буферами может целиком возлагаться на пользователя. Существуют и методы, предоставляющие пользователю выбор относительно того, пользоваться услугами системы для управления буферами или нет.
Методы доступа системы DOS. Все методы доступа Дисковой операционной системы предполагают полуавтоматическое управление буферизацией. Для обеспечения возможности работы системы необходимо зарезервировать внутри своей программы одну или две буферных области. Если работа производится с двумя буферными областями, то выполнение всех операций ввода-вывода при работе с последовательными файлами производится системой еще до получения реальных запросов. Пользователь может заказать блокирование данных при выводе и разблокирование при вводе. В системе DOS возможны следующие способы организации наборов данных: последовательный, индексно-последовательный и прямой. Основными методами доступа системы DOS являются:
Последовательный метод доступа (SAM)
Индексно-последовательный метод доступа (ISAM)
Прямой метод доступа (DAM)
Таблица 17.1 Некоторые методы доступа системы OS
|
Наименование |
Мнемоника |
Функции |
|
Queued Sequential Access Method |
QSAM |
Последовательная организация данных, способ доступа с очередями |
|
Basic Sequential Access Method |
BSAM |
Последовательная организация данных, базисный способ доступа |
|
Queued Indexed Sequential Access Method |
QISAM |
Создание и последовательная обработка индексно-последовательных файлов |
|
Basic Indexed Sequential Access Method |
BISAM |
Произвольная обработка индексно-последовательных файлов |
|
BasicPartitioned Access Method |
BPAM |
Создание и обработка библиотечных наборов данных |
|
BasicDirect Access Method |
BDAM |
Обработка файлов с прямой организацией |
|
TelecommunicationsAccess Method |
TCAM |
Взаимодействие с удаленными терминалами |
Методы доступа системы OS. Методы доступа операционной системы OS распадаются на два класса: базисные методы доступа и методы доступа с очередями. Методы доступа с очередями обеспечивают полностью автоматическое управление буферизацией. Система сама заботится о ведении буферных областей. Система же производит блокирование и разблокирование записей. Методы доступа с очередями используются при обработке последовательных и индексно-последовательных файлов. Эти методы позволяют достичь максимальной эффективности обработки при минимуме требований, предъявляемых к программе пользователя.
По сравнению с методами с очередями базисные методы доступа являются гораздо более примитивными. Тем не менее, они позволяют достичь большей гибкости работы с данными. Часть обязанностей по управлению буферизацией теперь возлагается на пользователя, кроме того, на пользователя возлагается и разблокирование записей. Базисные методы доступа используются в основном, когда приходится иметь дело с непоследовательной обработкой наборов данных. Список наиболее употребительных методов доступа системы OS приведен в табл. 17.1.
В своем рассмотрении мы лишь слегка затронули вопросы, связанные со структурами данных и предоставляемыми операционной системой возможностями выполнения операций ввода-вывода. Тем не менее, этого материала достаточно для того, чтобы приступить к обсуждению использования методов доступа при программировании ввода-вывода. В дальнейшем нас будут интересовать лишь последовательные методы доступа с очередями систем OS и DOS. Несмотря на то, что принцип использования последовательного метода доступа с очередями является общим для двух изучаемых нами систем, конкретные детали все-таки достаточно сильно различаются. Целесообразно рассмотреть лишь материал, связанный с программированием ввода-вывода в вашей конкретной системе. После этого, однако, вы можете просмотреть и другой раздел с целью знакомства со сходными моментами в работе с двумя системами.