Иерархическая модель (древовидная)
Представляют собой упорядоченную совокупность экземпляров данных типа «дерево», содержащих экземпляры типа «запись». Корневым называется тип, который имеет подчиненные типы, а сам подтипом не является. Подчиненный тип (подтип) является потомком по отношению к типу, который для него является предком.
Плюсы:
- Эффективное использование памяти ЭВМ;
- Малое время выполнения операций над данными.
Минусы:
- Громоздкость;
- Сложные логические связи;
- Сложное понимание.
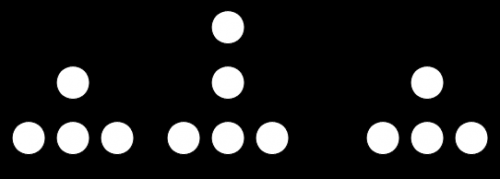
Рис.2.1 Иерархическая модель
Сетевая модель
Позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа.
Для описания сетевой БД используются две группы типов:
- Запись;
- Связь;
Тип связи определяется для двух типов «запись»- предка и потомка.Запись потомок может иметь произвольное число записей предков.
Плюсы:
- Эффективная реализация по показателям затрат памяти и оперативности;
- Большие возможности для образования произвольных связей.
Минусы:
- Высокая сложность и жесткость БД
- Сложность понимания и выполнения обработки информации в БД
- Ослаблен контроль целостности связей.
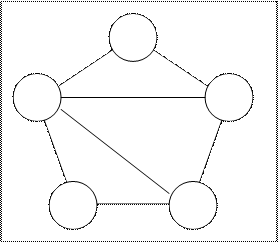
Рис.2.2 Сетевая модель
Иерархическая модель – таблица
Таблица имеет строки (записи) и столбцы (колонки). Любая строка имеет одинаковую структуру и состоит из полей.
Плюсы:
- Простота, понятность, удобство физической реализации на ЭВМ.
Минусы:
- Отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Постреляционная модель
Расширенная реляционная модель, снимающая ограничение неделимости данных, хранящихся в записях таблиц.Постреляционная модель допускает многозначительные поля – поля значения, которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную.
Преимущества:
- Возможность предоставления связанных реляционных таблиц одной постреляционной.
- Высокая наглядность информации и повышенная эффективность ее обработки.
Недостатки:
- Сложное решение проблемы обеспечения целостности и непротиворечивости данных.
Многомерная модель
Узкоспециализируемые СУБД, предназначенные для интерактивной аналитической обработки информации.
Основные понятия, используемые в многомерной модели
Агрегируемость – рассмотрение (данных) информации на различных уровнях ее обобщения.
Историчность данных предполагает обеспечение высокого уровня статичности данных и их взаимосвязей, а так же обязательность привязки данных по времени.
Прогнозируемость подразумевает задание функции прогнозирования и применение их к различным временным интервалам.
Преимущества:
- Удобство и эффективность аналитической обработки больших объемов информации, связанных со временем.
Недостатки:
- Громоздкость для построения задач обычной оперативной обработки информации.
Объектно-ориентированная модель
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи БД. Между записями БД и формами их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования. Строка объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описывается некоторыми стандартным типом (П : string)или типом (используемым) конструируемым пользователем (class). Каждый объект – экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект – экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в БД образуют связную иерархию объектов. Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное отличие между ними – в методах манипулирования данными.
Преимущества:
- Возможность отображения информации о сложных взаимосвязях объектов;
- объектно-ориентированная модель БД позволяет идентифицировать отдельную запись БД и определить функции их обработки.
Недостатки:
- высокая понятийная сложность;
- неудобство обработки;
- низкая скорость выполнения запросов.